Esta entrada es un poco distinta de lo que suelo escribir, ya que normalmente intento (con mayor o menor éxito) escribir para un público no especializado en lingüística. Hoy, sin embargo, escribo algo que seguramente sea de poca utilidad a aquellos que no son lingüistas y no trabajan con corpus (aunque espero que sí sea del gusto de aquellos que sí), así que me disculpo de antemano. Por si su curiosidad es más fuerte que mi advertencia y van a leerme igual, les explico primero qué es un corpus lingüístico: se trata de un conjunto de textos recopilados con el objetivo de hacer investigaciones lingüísticas. Pueden ser textos literarios, textos jurídicos, transcripciones de entrevistas; pueden ser textos de distintos periodos o de una franja temporal limitada, etc. Los corpus actuales suelen estar disponibles online y constar de una herramienta de búsqueda (con distintos grados de sofisticación).
En la mesa redonda del último día del CIHLE, Virginia Bertolotti le preguntó a Andreas Dufter cuál sería su corpus ideal para estudiar el latinismo sintáctico. Inspirada por esa pregunta, me he puesto a soñar en mi corpus ideal (para estudiar cualquier cosa). La lista que sigue contiene sobre todo una serie de deseos de carácter práctico (y no metodológico, aspecto en que creo que la lingüística hispánica tiene una situación envidiable respecto de muchas otras lenguas, con menos corpus y de peor calidad filológica). Ya, sin más preámbulos, mi carta a los Reyes Magos de Corpusiente (me disculpen el chiste, tenía que).
1. Lematización para guardarse las espaldas
Personalmente, desconfío bastante de la lematización (asignación a cada palabra de su correspondiente forma de diccionario, para poder recuperar, por ejemplo, las formas señora, señores y señoras si busco el lema señor) y el etiquetado (asignación a cada palabra de sus rasgos gramaticales, para poder buscar todos los verbos, o todos los sustantivos masculinos plurales, etc.) automáticos. Es cierto que la mayoría de softwares tienen un nivel de acierto bastante elevado, pero siempre he creído que los casos más difíciles de etiquetar automáticamente seguramente lo serán por ser los más interesantes y me parece absurdo arriesgarnos a perdérnoslos por confiar en un programa que se equivoca unas dos o tres veces por cada cien palabras.
Por eso preferiría una lematización y un etiquetado “de seguridad”, que en vez de escoger una etiqueta para las formas ambiguas (¿es cosa una forma verbal —El que mejor lo cosa, gana— o un sustantivo —Te voy a decir una cosa—?) les asignara las dos. Por supuesto, esto aumentará el caso de falsos positivos (encontrar muchos cosa verbales cuando me interesa el sustantivo), pero estos me parecen preferibles a los falsos negativos (perderme muchos cosa sustantivos que la máquina ha considerado verbales).
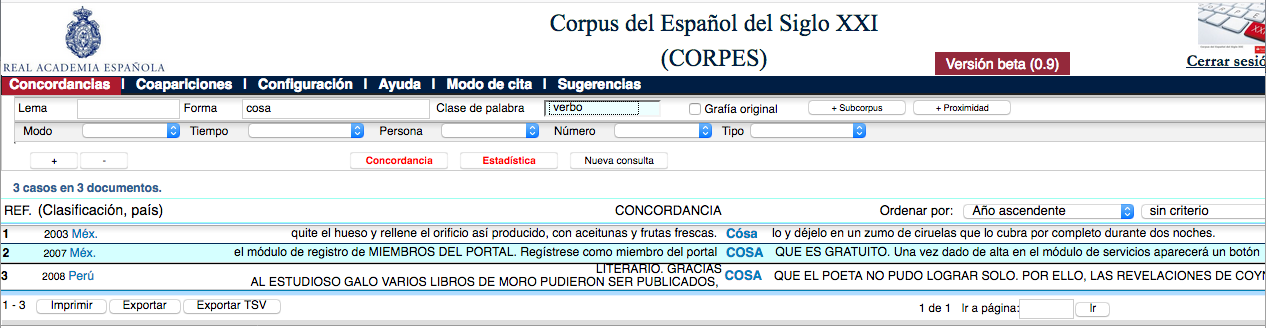 El CORPES se hace un lío cuando le pedimos que nos devuelva los casos de cosa verbal
El CORPES se hace un lío cuando le pedimos que nos devuelva los casos de cosa verbal
2. Contexto suficiente de los resultados
Que los ejemplos tengan un contexto suficiente para que podamos descifrar bien el significado de las formas que nos interesan es absolutamente esencial (se lo dice una que dedica mucho tiempo a leer ejemplos con una de las formas más ambiguas de nuestra lengua: el famoso se). Pero muchos corpus son algo tacaños con el contexto que ofrecen. Es habitual que uno pueda acceder a más contexto pinchando en el ejemplo (así lo hacen los corpus de las Academias, véase el CORPES arriba), pero esa es una opción muy incómoda si hemos descargado los resultados para trabajar con ellos en algún tipo de hoja de cálculo (que es, desde luego, la forma óptima de trabajar, voy a ello en el siguiente punto). Una opción sería permitir que el usuario elija cuánto contexto previo y posterior quiere (medido en caracteres, palabras, oraciones, párrafos…), pero también sirve lo que hace el COSER, por ejemplo, que da siempre un contexto muy abundante (creo que con las dos intervenciones anteriores y las dos posteriores). Respecto al contexto vale la misma regla de oro que para todo lo demás: mejor que sobre que que falte.
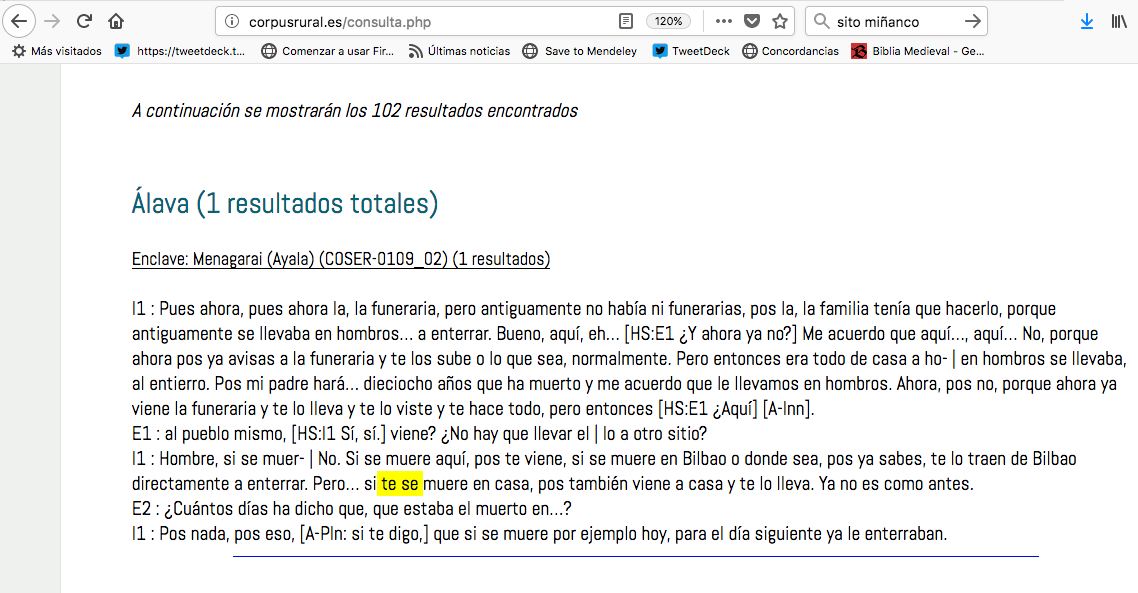
El COSER no se corta con el contexto
3. Exportación de resultados
Este aspecto tan fundamental es, me parece, uno de los que está más descuidado en nuestros corpus. Poder exportar los datos rápidamente y de golpe a una hoja de cálculo (idealmente con una codificación estándar, que para algo se ha inventado el UTF-8).
Quizá la cosa más irritante del CDH sea que no hay un botón de exportar los resultados, a pesar de que el CORPES sí tiene uno. Seriously, RAE, de qué vas. Y si bien es cierto que el CORPES tiene una herramienta de exportación, ¿por qué no permite exportar todos los resultados a la vez? ¿Por qué solo de página en página? Las páginas pueden tener un máximo de 60 resultados, por lo que una búsqueda modesta, con 1000 resultados, requiere por lo menos 17 archivos, lo cual es, simple y llanamente, un disparate. ¿Y por qué en .txt? No pueden abrirse directamente en una hoja de cálculo, sino que hay que copiarlos y pegarlos.
Aunque al escribir esto descubro que el CORPES ha mejorado su herramienta de exportación, porque, aunque en .txt, al menos ahora hay un formato que los ofrece tabulados. Esto es absolutamente fundamental, que los datos estén tabulados. Por favor. Es lo único útil, todo lo demás necesita mucho formateado previo a poder trabajar con ellos (i.e., ¡para tabularlos!). El CODEA cumple (¿¿cumplía??, ahora solo puedo copiar y pegar los resultados) bastante bien con este requisito, salvo por un pequeño detalle que puede convertirse en una pesadilla si se hace una búsqueda lematizada amplia: la exportación se realiza con archivos distintos para cada forma encontrada. Es decir, si buscamos la forma pod* debemos descargarnos manualmente 113 archivos, ¡pinchando individualmente en cada uno de ellos! Siendo lo más probable que luego vayamos a querer juntarlos (algo que puede hacerse fácilmente con un programa como R, sí, pero esta no es todavía la herramienta que más usa la mayoría de filólogos hispánicos): ¿por qué no podemos descargarlos todos de una vez?
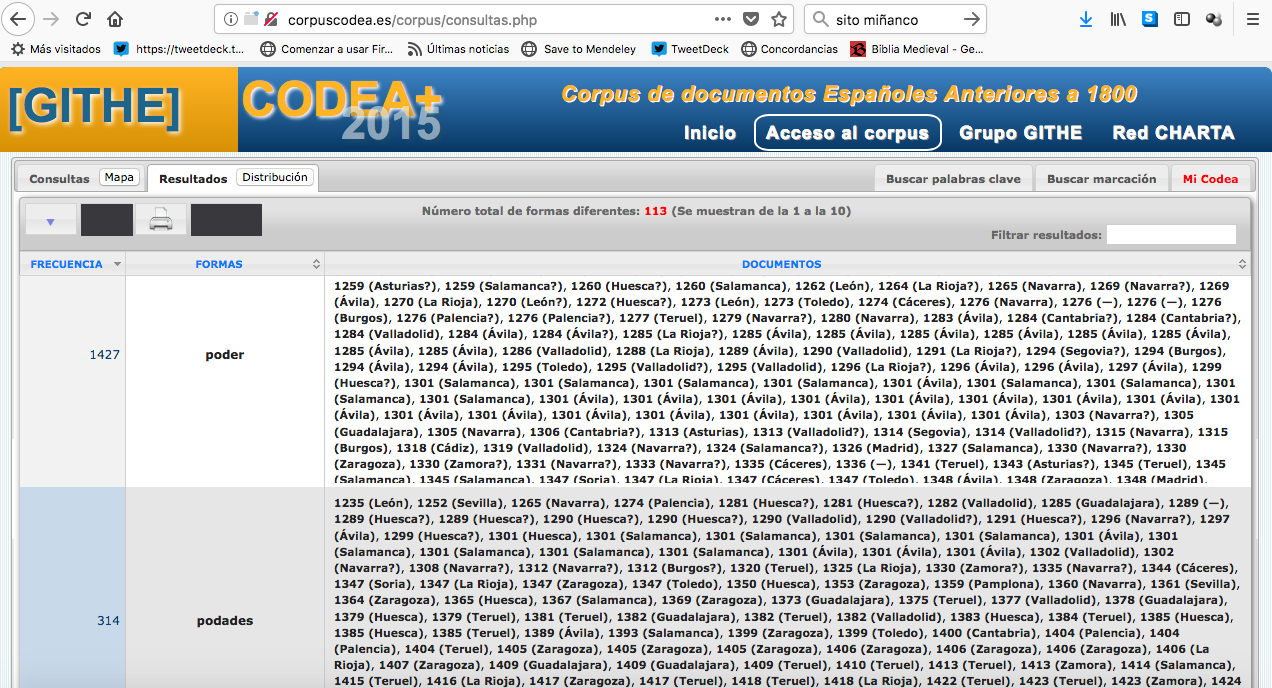
El CODEA ofrece un acceso diferenciado por forma a los datos
La realidad es que para poder ponernos a trabajar con los datos de la mayoría de nuestros corpus tenemos que dedicarle muchísimo tiempo a la preparación previa de los datos, cuando ofrecer el acceso a todos ellos de forma conjunta (y tabulada, ta-bu-la-da) debería ser algo extremadamente sencillo, pues se trata solo de cambiar el formato de la información que ya se da (y la presentación online suele ser tabulada). Por poner un ejemplo del absurdo, yo tengo un documento con las instrucciones que debo seguir para formatear los resultados del COSER a partir del código fuente de la página de resultados (que lleva mucho tiempo de cortar, pegar y remplazar en Word y Excel); un script para poder unir todos los archivos que devuelve CODEA (que lleva mucho tiempo de pinchar en archivos para descargarlos); otro script para descargar automáticamente el código fuente de los resultados de los corpus de la Academia que incluye tener que pasar las páginas de su web de forma automática (y que me llevó muchísimo tiempo escribir)… Es un dislate, con todo el pesar de mi corazón lo digo.
4. Ta-bu-la-ción y metadatos
Como no sé si he dejado suficientemente claro lo fundamental que me parece la tabulación de los datos, le voy a dedicar un apartado entero.
Hago antes un pequeño excurso, pues me pregunto si la renuencia a ofrecer los datos tabulados se debe a que existe mucho escepticismo frente a Excel (o cualesquiera de sus miles de equivalentes, muchos gratuitos: holi, Open Office) en nuestro campo. No sé si es por desconocimiento o por tradición, pero el estilo de trabajo casi pidaliano, con fichas a mano o en un Word, contando ejemplos de cabeza no ha desaparecido… Si este es vuestro caso y me permitís datos un consejo, por favor, id corriendo a abrir Excel. Sé que la primera vez que uno lo abre, se asusta. Y que da mucha pereza aprender a usar un programa nuevo. Que la curva de aprendizaje no es un mito, sino una frustración constante. Pero si le dedicáis un ratito, de verdad, solo un ratito, os vais a ahorrar millones de ratitos futuros. Con corpus que exporten los datos adecuadamente y un manejo normalito de Excel todos doblaríamos el número de artículos por año. O, mejor todavía, disfrutaríamos del doble de vacaciones. Trabajaríamos menos en finde. Se me hace la boca agua.
¿Por qué importa Excel? Porque una vez que tenemos los ejemplos metidos en una hoja de cálculo (debidamente tabulados, ahora voy a ello), Excel los puede contar de forma automática. Se pueden clasificar los ejemplos para diversos parámetros de una sola vez, sin tener que volver una y otra vez a Word o la corpus online. Se puede añadir un nuevo parámetro cómodamente (sin tener que volver a realizar la búsqueda). ¡Hay hasta filtros que permiten seleccionar ejemplos de un determinado tipo y contarlos automáticamente! Excel es calidad de vida, palabrita.
¿Y cómo debe ser la tabulación? Característica primera y fundamental: cada ejemplo debe ir en una fila distinta de nuestra hoja de cálculo. Aquí es problemático el formato actual del COSER, por ejemplo, precisamente porque da mucho contexto: si hay varios ejemplos de la búsqueda realizada que están muy cerca los señala dentro del mismo resultado. Esto complica luego el trasvase de los datos a un formato con el que trabajar, porque a) nos interesan los ejemplos individuales y b) a veces se repiten los resultados. Un ejemplo = una fila es la primera regla del club de los datos ordenados.
Segunda característica, también fundamental: el resultado directo de la búsqueda debe estar resaltado de alguna manera. Esto facilita su localización, especialmente si el contexto ofrecido es abundante, como debería, y hace que podamos trabajar más rápidamente. En el CIHLE se oyó alguna queja sobre que ya no leemos textos enteros, sino solo ejemplos sueltos, que cada vez hacemos menos trabajo propiamente filológico… En mi opinión, es fundamental combinar las dos tareas para trabajar de forma eficiente a la vez que rigurosa. Es decir, si me interesa codificar el género de los posesivos que siguen a detrás, no necesito leerme todo el ejemplo. Voy a leer muchos, de hecho, porque nuestros ojos no son capaces de aislar solo dos palabras y se van detrás de las demás, pero no lo necesito. Si me interesa saber la referencia de ese posesivo, en cambio, sí necesito leer los ejemplos y además necesitaré bastante contexto. Por eso necesitamos las dos cosas: contexto abundante y búsquedas resaltadas. Personalmente, me gusta mucho la manera en que se resalta la búsqueda en la red de corpus CHARTA, donde se da en una columna aparte, con el contexto previo en la columna de la izquierda y el posterior, en la derecha. Este formato es muy interesante porque, además de que los resaltados tipográficos corren el riesgo de perderse, permite organizar los ejemplos (usando el maravilloso botón de Excel para ordenar datos) a partir de los resultados, lo cual es muy útil para etiquetar rápidamente (usando la herramienta de rellenado automático de Excel, por ejemplo, o un sencillo cortaipega) categorías léxicas o morfológicas, como el género, el tiempo verbal, etc. Calidad de vida.
Tercera característica, absolutamente fundamental: metadatos. Todos los que podamos. Muchos corpus “racanean” también con esto, de manera que también haya que pinchar en los resultados para saber el año, el autor o el tipo de texto (los nuevos corpus de la Academia han empeorado en esto frente al CREA y al CORDE, por no meterme en los corpus de español en red como el Corpus del Español: Web/Dialects o el EsTenTen, que han sacrificado el catalogar mínimamente los textos por ofrecer grandes cantidades de datos). Tener que pinchar en los ejemplos nos quita años de vida otra vez. Nuestra herramienta de exportación debe dar todos los metadatos que tengamos (año, fecha, autor, código de documento en el corpus, localización —pueblo, provincia, país—, tipo de de texto…), cada uno en una columna distinta de la tabla. Y siempre mejor atomizar la información (si tenemos la información del pueblo, no darla como “Pueblo, Provincia” en una sola columna llamada “Ubicación”, por ejemplo, sino en dos columnas, una para pueblo y otra para provincia). También aquí, siempre, mejor que sobre que que falte.
Por último, numerar los resultados con un identificador único también es una buena práctica, aunque esto sí lo puede hacer de forma muy sencilla en Excel cada investigador. Lo dejamos como bonus 🙂
5. Acceso a los textos originales
Siempre que se pueda, me parece óptimo contar con acceso a una imagen del texto original o a la grabación para el caso de corpus orales, como hacen los corpus de la red CHARTA, Biblia medieval, CORDIAM, COSER, PRESEEA… Esto sí es algo muy frecuente en nuestros corpus y tiene que ver con el rigor que caracteriza a la escuela filológica española, así que solo puedo decir ¡viva!
Es más, muchos de estos corpus permiten la descarga de los textos completos, lo cual es fantástico. Ya que me pongo a pedir: aquí lo ideal sería darlos en formato txt (como Biblia medieval o Post Scriptum) y con una tablita de metadatos (¡por favor!), porque nos permite trabajar los textos desde programas externos con la flexibilidad que queramos dentro de nuestras posibilidades informáticas.
6. Descripción del corpus
Esto parece obvio, pero, por algún motivo que se me escapa, hay unos cuantos corpus que no explican cómo se han recopilado, cómo se han seleccionado los textos que se ofrecen o cómo se han transcrito. Me parece simplemente inaceptable. Sin nada más que añadir.
7. Un regalito para los directores del corpus
Acabo con una idea que, sobre todo, podría ayudar a los creadores de los corpus con solo un poquito de esfuerzo por parte de los usuarios (que mucho tenemos que agradecer a los primeros, por cierto). La idea tiene que ver con el primer punto, respecto de la lematización y el etiquetado automáticos y se trataría de un pequeño botón que permitiera marcar aquellos ejemplos que no corresponden a la búsqueda realizada y que guardara esa información para que los directores de los corpus pudieran revisarlo. Esto ayudaría a detectar y solucionar errores de forma eficiente y colaborativa. El COSER tiene una herramienta más o menos similar, que te permite descartar los resultados que no te interesen: en este caso se trataría de marcar aquellos que no se corresponden con la búsqueda realizada por un error de la lematización o del etiquetado. Los responsables de los corpus luego pueden revisarlo (o no, si deciden confiar ciegamente en sus usuarios) y así el corpus mejora poco a poco. Y lo mismo podría decirse de errores de transcripción o lectura: creo que no estaría de más que los usuarios pudieran ayudar a los creadores de corpus proponiendo mejoras o cambios de las transcripciones cuando crean que son necesarios.
Concluyo: no puedo agradecer suficientemente a todos aquellos que compilan corpus su labor. Mi vida y la de otros lingüistas es increíblemente más sencilla gracias a ellos y tienen toda mi admiración, porque sé lo exigente y agotador que es. Espero que esta carta de deseos les sirvan, si consideran que pueden ser útiles. Creo que la mayoría no son difíciles de implementar y no dan mucho más trabajo, pues solo requieren ofrecer de forma más eficiente información que ya está disponible (y organizada) de alguna manera. Quizá pido muchas cosas, pero soñar es gratis y eso es a lo que nos invitaba Virginia con su pregunta. Y, vosotros, ¿qué le pediríais a vuestro corpus ideal? ¿Qué os parecen mis ideas? 🙂
** Disclaimer **: Excel no me ha pagado un duro por escribir esta entrada. Que ya se podrían estirar en Microsoft, pero nada.
 Follow
Follow